

RonDB is a database specialized for building machine learning pipelines.
One example of a real-time AI system is Spotify’s personalized recommendation system, where Spotify gathers information about the music a person looks for and listens to and feeds that data into an AI model trained on historical data. The system is an active real-time system when the user awaits a response.The figure below visualizes how the request is created in a web client and travels the Internet to a web farm where it is eventually directed to an inference engine that will handle the request.
The figure below visualizes how the request is created in a web client and travels the Internet to a web farm where it is eventually directed to an inference engine that will handle the request. The benchmark setup used 2 Availability Zones to ensure we ran the benchmark with a proper HA setup.
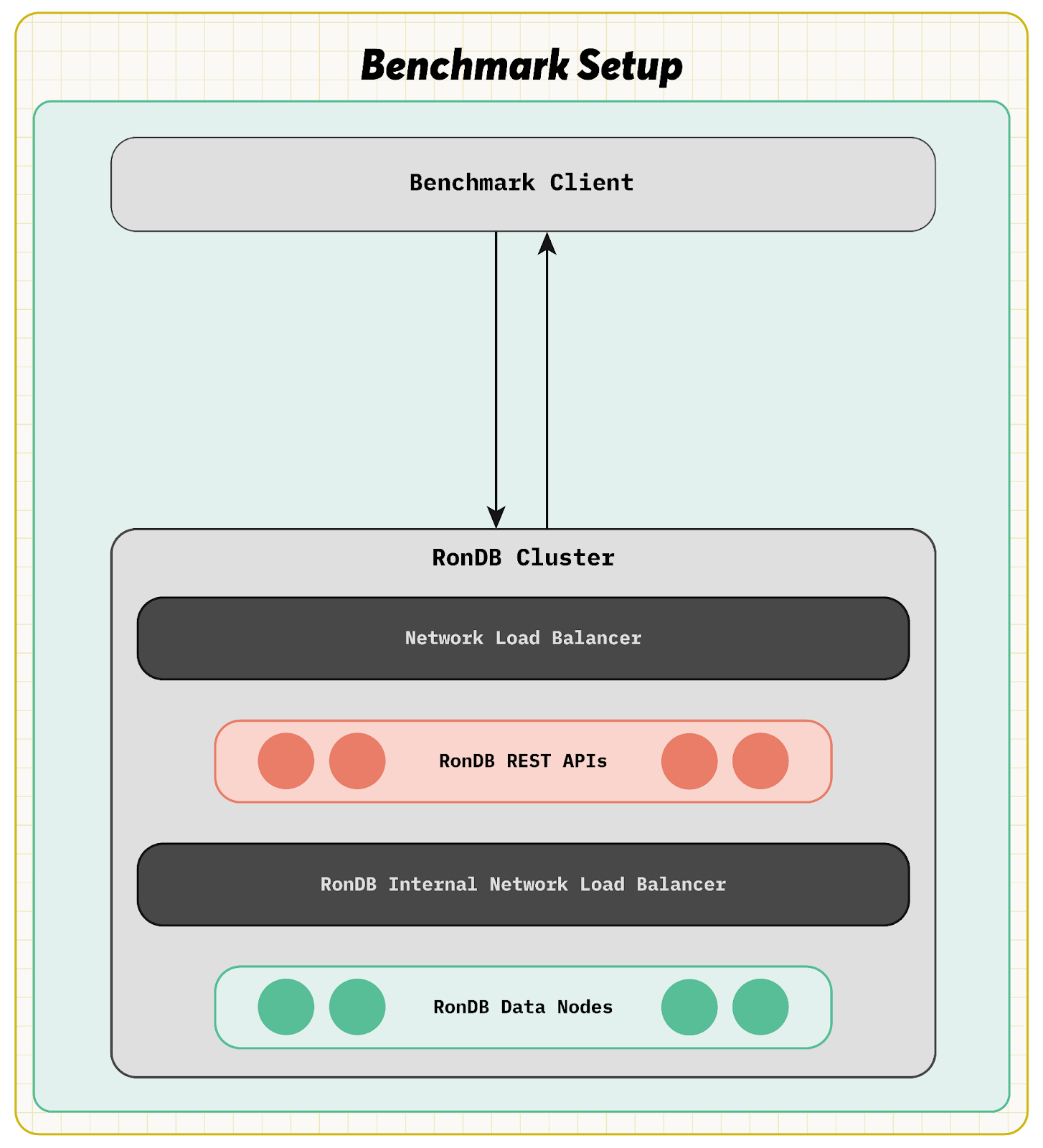
The inference engine has access to the Inference deployment using GPUs and the AI model that was created using the training data. The inference engine also needs a lot of features from the database. A personal recommendation system’s inference engine will request hundreds of features from the database to handle a single request by using primary key lookups [1].
RonDB is based on NDB Cluster, which showed 10 years ago that it is possible to deliver hundreds of millions of key lookups per second [2]. This benchmark shows that it is possible to deliver those same results in a modern development environment using a REST API and that each request can retrieve hundreds of records in milliseconds.
RonDB 24.10 includes a new REST API interface for AI models, making it possible to request a batch of records from a set of tables using key lookups. This REST API interface was implemented in C++ using the simdjson [3], speeding up the JSON parsing by a factor of 30. This new RonDB REST API performs anywhere from 30% to 900% better in throughput and latency when compared to the REST API interface in RonDB 22.10. RonDB’s REST API has both a traditional database interface and a specialized interface for feature store requests, both of which support batch requests. The capability to issue a batch of requests to more than one table is not a common feature in other key-value stores. What makes RonDB unique is that the batch interface can be used with extremely low latency for the entire batch requests.
The RonDB team decided to take on the challenge of showing how RonDB can deliver 100 million key lookups per second through the REST API. As a result, RonDB successfully delivered 104.5 million key lookups per second with 5 integer features per record. We also ran a test with 10 features, half integer and half string, per record. This test reached 96.4 million key lookups per second, delivering 125 Gbit per second, or 15.6 GBytes per second, of JSON data to the benchmark clients.
The benchmark involved 6 RonDB data nodes with 64 CPUs each, 36 RonDB REST API servers with 16 CPUs each, and 22 clients with 64 CPUs each. The clients used the Locust tool, therefore the application was written in Python. 4221 clients were active in those tests. Each batch request asked for 150 rows.
The benchmark also included a latency test, where the number of clients was decreased to 1407, resulting in 61.5 million key lookups per second. The average latency was 1.93 milliseconds, the 95% latency was 2 milliseconds, and the 99% latency was 3 milliseconds. In this case, the number of rows per batch request was 100.
These numbers prove that it is possible to scale a personal recommendation system to millions of batch requests with hundreds of rows per batch.
Now most databases report numbers of single key lookup latencies and throughput. The benefit of RonDB is that it can parallelise a batch request very efficiently. To demonstrate this we also made a latency benchmark where we demonstrate the latency from the Python scripts point of view (End-to-End latency) and the latency from receiving the request in the REST server until it is sent back to the client. The End-to-End latency also includes time spent by Python to process the request. The below graph shows the average latency and P99 latency for those.
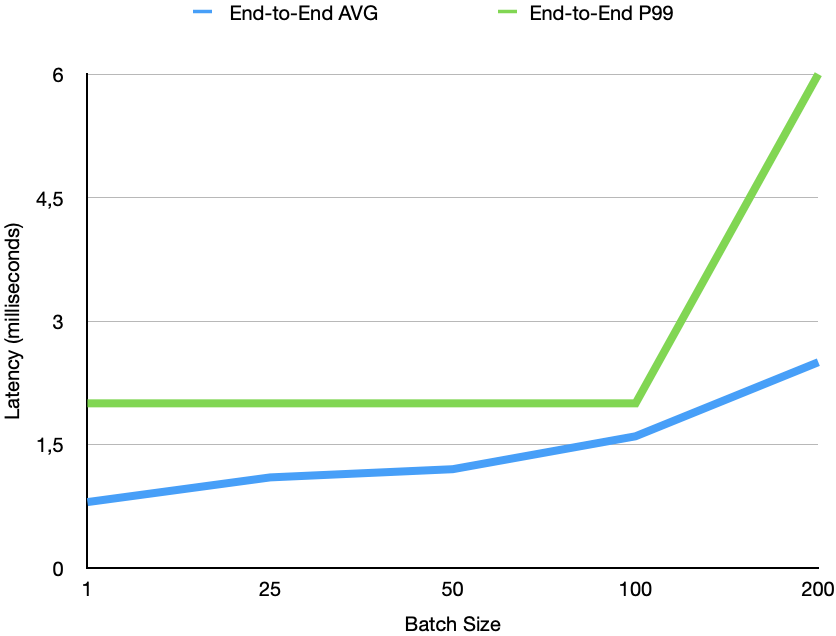
The above graph shows that End-to-End latency is almost as low as the single key lookup, so going from 1 key lookup to retrieving 100 key lookups only increases P99 latency from 820 microseconds to 1640 microseconds. Thus 100x more rows fetched only extends the latency by 2x. With more than 100 rows the latency starts to increase more, this is mostly due to the number of partitions and number of CPUs used in this benchmark.
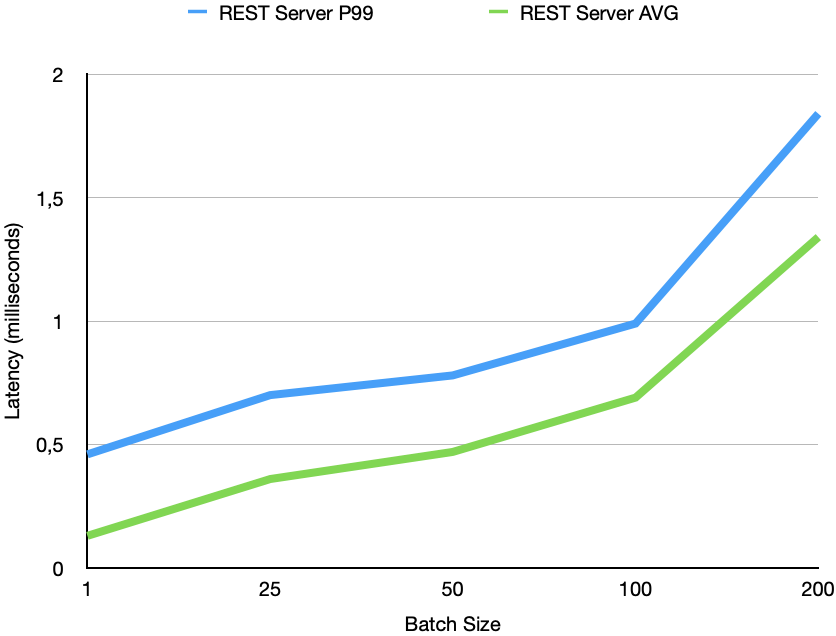
In the graph below we can see the latency of the REST server from receiving until it sends the response. This data is collected from Grafana and will be available also in our RonDB demo cluster. We see that the P99 latency goes from 460 microseconds to 995 microseconds when going from a single key lookup to a batch of 100 key lookups. Thus again the latency only increases with 2x when the number of rows increases by 100x.
The low latency of batch requests makes RonDB uniquely qualified to be the Key-value Store for AI applications such as Personalised Recommendation Systems.
[1] Alexanders master thesis at Spotify
(https://www.diva-portal.org/smash/get/diva2:1556387/FULLTEXT01.pdf)
[2] Blog on 200M key lookups per second
(https://mikaelronstrom.blogspot.com/2015/03/200m-reads-per-second-in-mysql-cluster.html)
[3] Reference to simdjson
(https://github.com/simdjson/simdjson)
Powered by Hopsworks © RonDB 2025. All rights reserved


