

Recently, we announced that RonDB delivered more than 100 million key lookups per second in a single cluster in a real-time AI benchmark [1]. In this article we will tell you what we learned from building a 100M key lookup system on AWS. This 100M key lookup system will be 99.99995% lower in cost compared to using DynamoDB.
The Python clients used REST API requests towards the RonDB REST API servers to get the rows.
The benchmark results successfully delivered 104.5 million key lookups per second with five integer features per record. We also ran a test with ten features (half integer, half string) per record. That second test reached 96.4 million key lookups per second, delivering 125 Gbit per second (or 15.6 GBytes per second) of JSON data to the benchmark clients.
The benchmark involved 6 RonDB data nodes with 64 CPUs each, 36 RonDB REST API servers with 16 CPUs each, and 22 clients with 64 CPUs each. The clients used the Locust tool, therefore the application was written in Python. 4221 clients were active in those tests. Each batch request asked for 150 rows.
The benchmark also included a latency test, where the number of clients was decreased to 1407, resulting in 61.5 million key lookups per second. The average latency was 1.93 milliseconds, the 95% latency was 2 milliseconds, and the 99% latency was 3 milliseconds. In this case, the number of rows per batch request was 100.
This blog is an in-depth dive into what work was done to reach more than 100 million key lookups per second in RonDB.
Below is a list of performance issues that had to be resolved in RonDB in the order of when the issues were solved while developing the benchmark:
These items were needed to get the benchmark to reach our goal, but some other work had been done before attempting this benchmark, including:
RonDB is a database specialized for building machine learning pipelines. Hopsworks, who develops and supports RonDB, has gone into detail about how RonDB meets the requirements of real-time AI systems [17].
One example of a real-time AI system is Spotify’s personalized recommendation system [18], where Spotify gathers information about the music a person looks for and listens to and feeds that data into an AI model trained on historical data. The system is an active real-time system when the user awaits a response.
The figure below visualizes a Personal Recommender System and how the request is created in a web client and travels the Internet to a web farm where it is eventually directed to an online inference program that will handle the request.
The online inference program uses inference GPUs and a user embedding model to calculate a vector to use in an ANN search in a vector index. The result from the ANN search is fed into a Ranking model and a number of candidates are fetched using a batch REST API request from the online Feature Store implemented by RonDB. The online inference program uses the ranking model and the fetched rows to calculate the recommendations. A personal recommendation system’s inference program will request hundreds of features from the database to handle a single request by using primary key lookups [18].
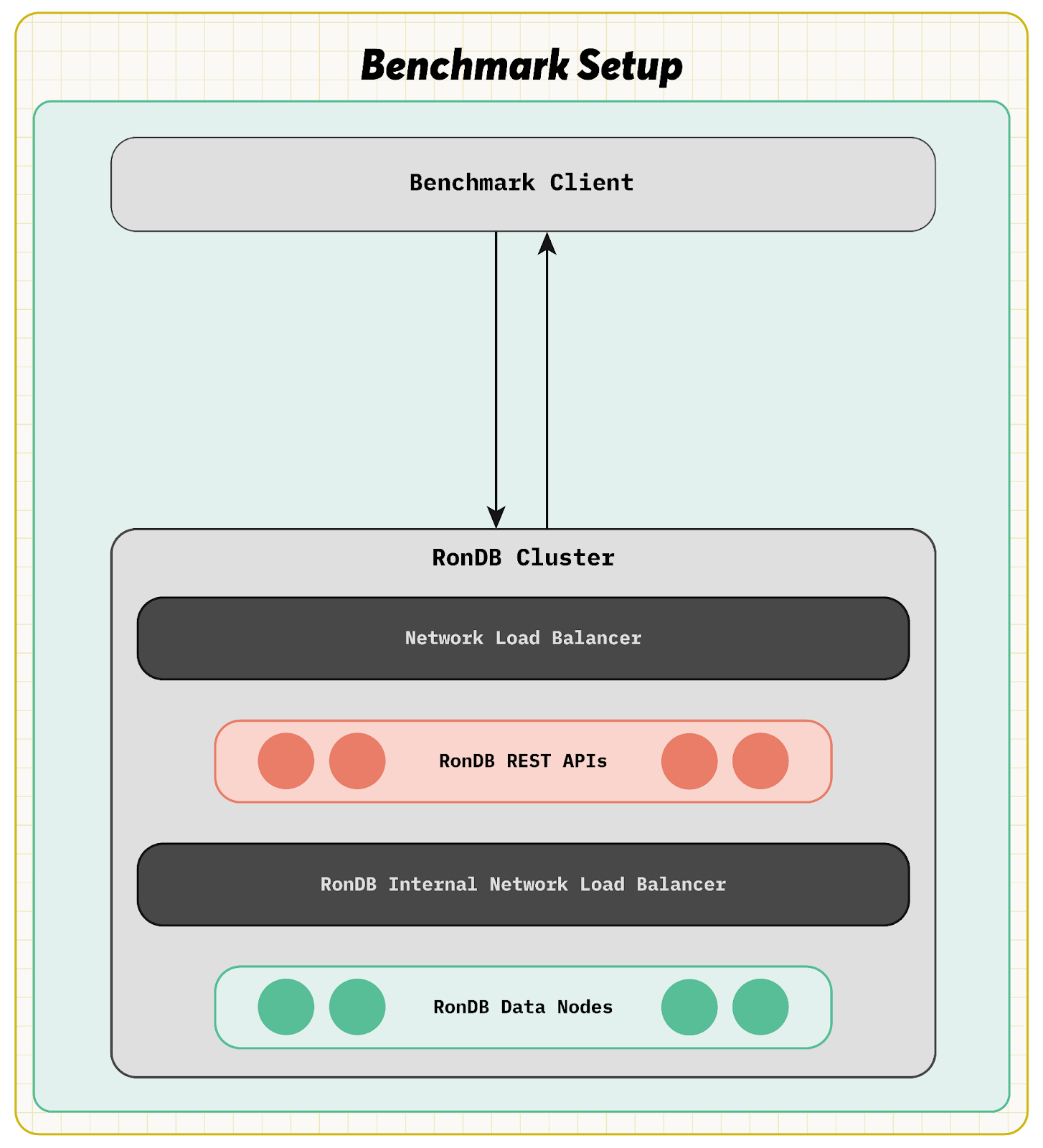
Now in the benchmark we have focused on the retrieval of rows for the ranking model as seen in the figure below.
RonDB is based on NDB Cluster, which showed 10 years ago that it is possible to deliver hundreds of millions of key lookups per second [19]. This benchmark shows that it is possible to deliver those same results in a modern development environment using a REST API and that each request can retrieve hundreds of records in milliseconds.
RonDB 24.10 includes a new REST API interface for AI models, making it possible to request a batch of records from a set of tables using key lookups. This REST API interface was implemented in C++ using the simdjson [14], speeding up the JSON parsing by a factor of 30. This new RonDB REST API performs anywhere from 30% to 900% better in throughput and latency when compared to the REST API interface in RonDB 22.10. RonDB’s REST API has both a traditional database interface and a specialized interface for feature store requests, both of which support batch requests.
The RonDB team decided to take on the challenge of showing how RonDB can deliver 100 million key lookups per second through its REST API, exemplifying how RonDB can deliver responses of up to millions of batch requests per second for personalized recommendation systems.
Running a benchmark that handles millions of batch requests requires clusters using thousands of processors. The first step in creating such a benchmark is to create a simple tool that quickly creates RonDB clusters, installs the necessary software, starts RonDB, and runs the benchmark clients.
The team decided on using Terraform to create the VMs required by the RonDB cluster. This included creating virtual networks, routers, load balancers, and other requirements to build a large, distributed cluster. We had some assistance from ChatGPT in accomplishing this.
The next step was to create an installation script that installed all the required software, including the RonDB software. The installation process of a large cluster takes a while, as it is important to ensure that the process does not overwhelm the servers from where the software is downloaded.
The first cluster we created was rather small, consisting of only 2 data nodes. We quickly discovered that the performance would not go beyond 2.5 million key lookups per second. After using perf, a performance tool in Linux, and testing, we discovered that the problem was because the table had too few partitions.
The test used a single table, which can have multiple readers concurrently but not an unlimited number. The default setting meant that the table had four partitions, which each could handle around 600,000 key lookups per second. The default setting also assumes that there are many tables. In Hopsworks, each feature group is a table in RonDB. There can be hundreds and even thousands of these tables. Coming across such a bottleneck of having too few partitions is not usual as there are options when creating the table to ensure that the number of partitions is larger and there is also a configuration setting to increase the number of partitions for all new tables.
When in production, this issue has never occurred. Hopsworks has a feature to ensure that the number of partitions can increase up to 16 times.
When running data nodes with 64 CPUs, the team discovered that the number of send threads needed to be 6 instead of 5, decreasing contention of the send mutexes.
To create the table, we used NDB_TABLE=PARTITION_BALANCE=FOR_RP_BY_LDM_X_16. This comment ensured that the default number of partitions increased by a factor of 16. We also set the configuration parameter PartitionsPerNode from 2 to 4. The number of partitions increases with the number of nodes. Starting with 6 partitions, increasing partitions by a factor of 16, and then increasing partitions per node to 4 meant that the benchmark used 384 partitions, which will be more than enough to handle 100 million key lookups without concurrency limits.
In the first test, we noticed that the REST API servers did not deliver the expected throughput. The number of threads used was only 16, which would not ensure all 16 CPUs were busy. Increasing the number of threads to 64 nearly doubled the throughput per REST API server. Next, we disabled compression of the responses, as it used too much CPU to be beneficial. This practice is helpful in scenarios where network bandwidth is limited and CPUs are in abundance. Finally, the team experimented with the optimal sizing of the REST API server and how many cluster connections to use. We discovered that using 16 CPUs per REST API server with 2 cluster connections was the most optimal configuration, allowing the REST API servers to deliver 3.5 million key lookups per second each. These fixes led to us achieving 22 million key lookups per second.
In AWS, users can choose either an Application Load Balancer that performs at the HTTP level or a Network Load Balancer that operates at the TCP level. This Network Load Balancer is used between benchmark clients and the REST API servers.
In a production setup with Hopsworks, communication with the REST API likely comes from within a Kubernetes cluster. In this case, an internal Kubernetes load balancer can be used, but an external network load balancer is required to communicate with the Hopsworks application.
We started out with an Application Load Balancer, achieving 22 million key lookups. However, it scaled very slowly, taking five to six runs of several minutes before it reached its optimum.
The Network Load Balancer worked far better. It scaled much faster and achieved roughly 25 million key lookups in its first benchmark run. However, it still requires some warmup before achieving maximum capacity, meaning that it could improve with each run.
We realized that the AWS Network Load Balancer will always choose a REST API server in the same availability zone. This led to the discovery that it was limited to around 50Gb per second in a single availability zone, leading us to determine that more than one availability zone was required to achieve the goal.
Communication between the RonDB REST API and the RonDB Data node uses the NDB protocol implemented by the NDB API. This protocol handles load balancing by sending requests directly to a node that has a replica of the data. RonDB also includes features that localizes reads within a single availability zone, which will be discussed further later on. This means that there is no need to use a load balancer in communicating between the REST API server and the RonDB data node.
There were three potential CPU types to use in the benchmark: the c7i series, which is a 4th generation Intel Xeon; the c7a, a 4th generation AMD Epyc; an ARM processor from AWS, Graviton 4. ARM has never been used in any benchmark of RonDB or NDB Cluster, as the port to ARM is a fairly recent addition. 5th generation Intel and AMD CPUs were not yet available in AWS, though they were released to the market nearly a year ago.
We tested which CPU type was optimal to run the REST API server and which CPU type was optimal to run the RonDB data node. We determined that the Graviton 4 provided the best throughput per CPU, delivering about 20% more throughput for both the REST API and the RonDB data node. On benchmark clients (running Python code), the AMD VMs matched Graviton 4’s performance. It’s expected that the 5th generation AMD will be at least equal to the Graviton 4 and even outperform the Graviton 4 in some areas. We found that Intel VM types were around 20% slower than the AMD VMs.
The team elected to use the Graviton 4 VMs for the remainder of the benchmark. We came across a small glitch, as the region we used for the benchmarks, eu-north-1, only had 2 availability zones that had access to the c8g VM types. We still managed to achieve its goal, even within this limitation.
The choice of c8g held one drawback. The c8g.16xlarge (64 CPUs) has only a 30Gbit per second networking bandwidth. When running a single node group with 2 replicas, the networking bandwidth becomes the bottleneck, not the CPUs in the RonDB data node. The c7i and c7a instances also have no instances with more bandwidth. There are c6 instances with extra networking bandwidth, however, those instances have much less CPU bandwidth. We have seen this issue with VMs not having enough network bandwidth before when running Sysbench OLTP benchmarks, which are even more network-limited.
To reach the desired goal required increasing the AWS quotas to reach 2500 CPUs. The quota on the AWS network load balancer was increased to 48.000 LCU, which is meant to handle 13.2 GBytes per second, but we achieved 15.6 GBytes per second.
When the team was close to achieving its goal, we came across an issue with the Locust client. When going beyond 1005 Locust workers, the master Locust started running at 100% CPU without doing any useful work. The problem was due to Locust requiring users to increase the maximum number of open files in Linux in the benchmark client that runs the master Locust process. After solving this issue, we used 1407 Locust workers in the final test run.
Handling multiple availability zones required some changes to the Terraform. These changes meant that we created VMs in the availability zones using a round-robin approach. However, RonDB needed to be aware of the placement of various nodes. RonDB solves this natively, using a configuration parameter called LocationDomainId. Thus, the config.ini that configures RonDB had to be updated as well to ensure the proper LocationDomainId was set on each node.
A batch request sends hundreds of key lookup requests in a single REST call. If one of those key lookup requests fail, the response will still return 200 OK on the batch request. The failed key lookups are part of the response message. This led to Locust reporting successful benchmarks with very high throughput, but after looking closely at the numbers, we realized that the numbers were reporting failed key lookups. All that this test had proved was that RonDB could handle hundreds of millions of failed key lookups per second.
The numbers did not scale how we were expecting them to, even after using multiple availability zones. We expected to have linear scaling from using one replica to using two replicas, but instead, the test’s performance improved by roughly 60% instead.
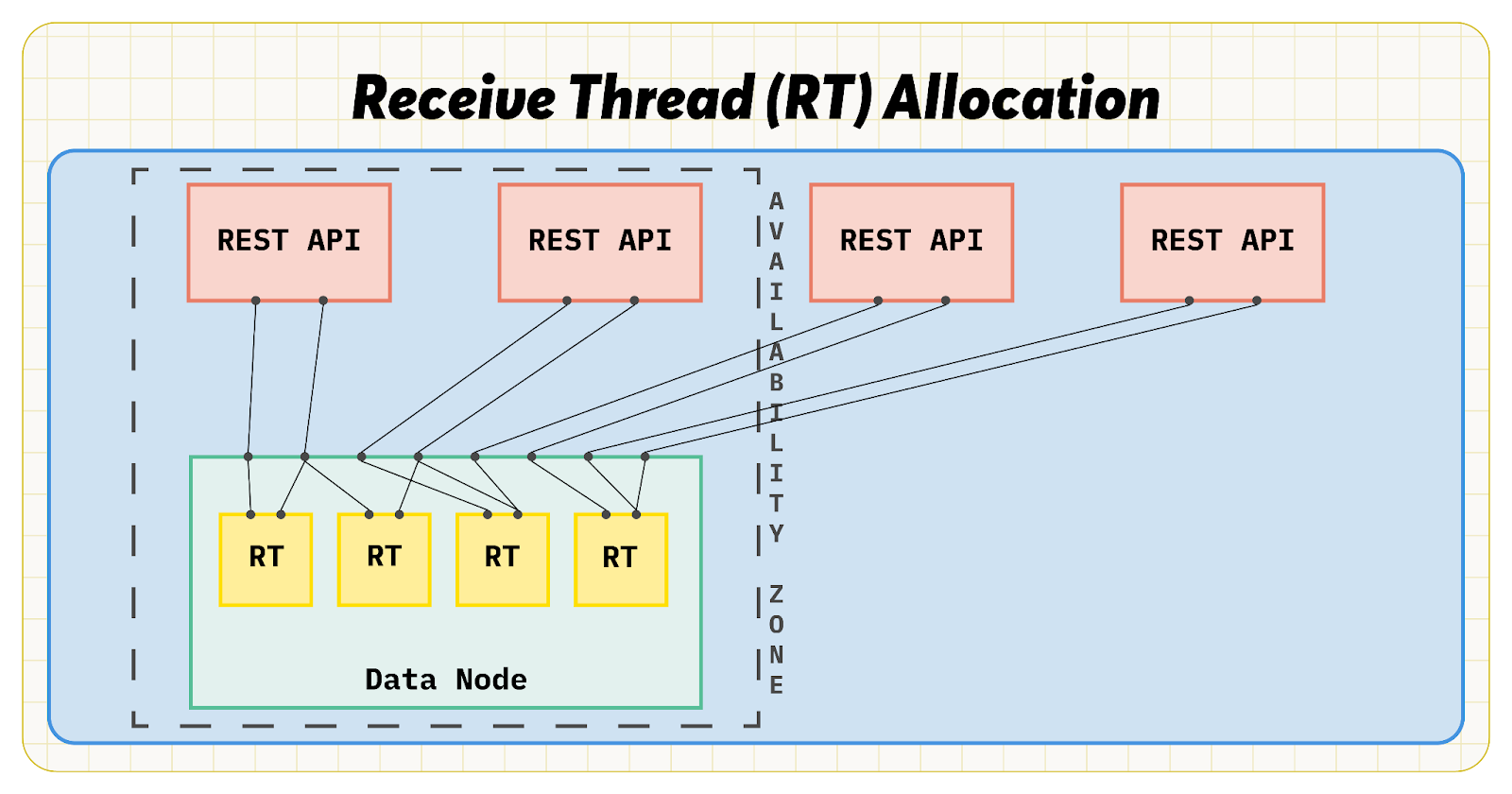
The figure below shows the issue. In RonDB data nodes, each cluster connection is allocated to a receive thread in a round-robin fashion. When using 2 cluster connections per REST API server and 2 availability zones, an anomaly arose that only half of the 8 receive threads got all cluster connections from the first availability zone and the other half were taking care of cluster connections from the second availability zone.Because RonDB is aware of the availability zones through the LocationDomainId parameter, reads only arrived on four of the receive threads. This was hidden, to some extent, by the fact that the receive threads were still assisting with reads, meaning the inactive receive threads were being used but not receiving.
The solution we used was to continue using a round-robin system, but instead assigning a cluster connection in a double loop, one availability zone at a time. This had a significant impact on scaling from one replica to two replicas in multi-availability zone setups.
The experiments showed that RonDB data nodes scaled well moving from 16 to 32 CPUs, but the gain increased by only 50% from 32 to 64 CPUs, which was not satisfactory. This is, to some extent, due to heavier loads on the CPU caches, but there were still potential improvements to be made.
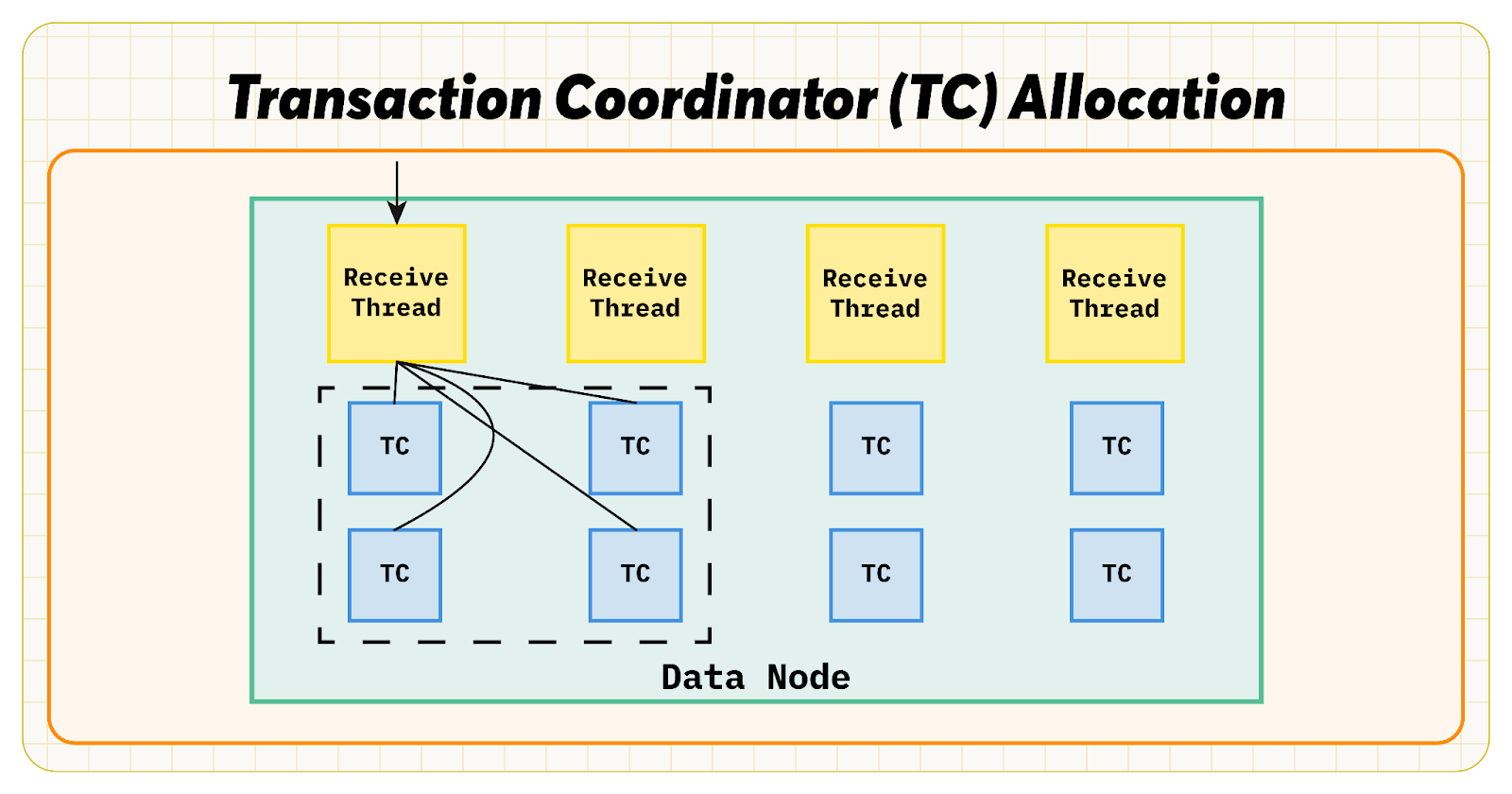
In the automatic thread configuration in RonDB data nodes, roughly half of the CPUs are assigned to the LDM threads (which only handle the actual database queries), a quarter of the CPUs are assigned as TC threads (which handle transactions and assist on read queries, and about one in eight CPUs are assigned as receive threads (which handle receiving network queries and assist on read queries).
When a transaction is started, it uses a connection to a RonDB data node. This connection is tied to a TC thread. When those connections are created, the TC thread is selected using a round-robin algorithm. This means that when a request arrives in a receive thread, the request can be passed to any 16 CPUs in a 64 CPU setup. Therefore, if a batch of 100 lookups arrive on the network, around 6-7 lookups will be sent to each of the 16 TC. To achieve good scalability, the team had to maintain the positive impacts of batching as much as possible.
Instead of each receive thread distributing transactions to all other TC threads, the receive threads should only distribute transactions to a subset of the TC threads, thus creating a sort of “island” in the data node. RonDB introduced this concept a few years ago in Round Robin groups. A Round Robin group shares at least the same L3 cache. The release of RonDB 24.10 increased the Round Robin group size from 8 to 16. By making the Round Robin group size configurable from 8 to 16 and ensuring that a receive thread only sent transactions to TC threads in the same Round Robin group, receive threads went from having 2 TC threads to 4 TC threads to distribute to. A group size of 8 Round Robin groups ended up being best in terms of performance. This change had a significantly positive impact.
One more problem in larger data nodes is the send algorithm. RonDB has a set of send threads that does the actual sending, while the other threads only prepare the sending. RonDB also has an adaptive assist send thread algorithm. This algorithm is in RonDB to speed up sending to avoid extra latency and is very beneficial in smaller nodes. However, in larger data nodes, this algorithm becomes too aggressive in sending. In nodes larger than 32 CPUs, RonDB disables the send assistance of LDM and TC threads.
RonDB also includes the configuration parameter MaxSendDelay, which is used to set a minimum time between two sends on the same cluster connection. In nodes larger than 32 CPUs, this parameter is set to 200 microseconds if the default, 0, is set. A non-zero setting will be setting the number of microseconds to wait at a minimum.
Both of these changes increase the scaling from 32 to 64 CPUs and significantly improves RonDB in large scale environments.
As mentioned earlier, there are also a set of older changes that have a major impact on the results of this benchmark.
To achieve a predictable low latency in real-time AI systems, it is important to control the allocation of threads to CPUs. This has been an important cornerstone in the development of RonDB data nodes since decades back as this allows RonDB to avoid the movement of threads to other CPUs with a different set of CPU caches. Such a move could temporarily slow down execution and cause an impact on both latency variation and throughput.
When receiving a batch of hundreds of key lookup requests, one can handle them all in one transaction. This is how, for example, the MySQL server would handle a query that does hundreds of key lookups. This means that the queries will need to all go through the same transaction coordinator, which could be in a different availability zone. Therefore, it is highly desirable that each key lookup is handled in a separate transaction. To accomplish this would require an asynchronous NDB API that can start hundreds of transactions in parallel from a single thread. This has been a part of the NDB API since the first production version of NDB Cluster.
If possible, it’s important to avoid the additional latency of waking up a thread in the RonDB data node. This latency is roughly 2-3 microseconds in a bare metal server, and around twice as much in a VM. RonDB calculates the impact of going to sleep. If RonDB is woken up within a short time after going to sleep, it might be beneficial to instead not go to sleep and save CPU time.
If there is nothing to do, but RonDB does not want to sleep, RonDB can spin. For example, the x86 has a PAUSE instruction that goes to sleep in a way that saves power and also does not impact other CPUs in any substantial way. THe main cost is other threads not being able to execute. Since RonDB is using CPU binding, RonDB normally does not have other threads waiting to be executed on the CPU.
Hence, it is often very beneficial for RonDB data nodes to spin. RonDB calculates the overhead of spinning constantly, and if the benefit outweighs the cost, RonDB will spin. If the thread is idle for long periods of time, it is often more efficient to go to sleep. RonDB has 4 levels of spinning: one is cost-based, one is optimizing on latency within reasonable cost, one optimizes on latency even at a very high cost, and the last uses static spinning (no adaptiveness in the spinning). Spinning decreases latency, though it does also increase throughput at low concurrency and there is a marginal improvement of throughput at high concurrency.
RonDB divides the work on executing queries in 4 parts: the receive from the network, the transaction coordination, the actual query execution, and the sending of the response.
There are at least three ways of handling this. One could do everything in one thread, which is the normal approach and uses synchronous programming methods. One could also do it all in different threads. Or someone could execute the parts using batching within a single thread. There are various pros and cons between these methods [5][6], but we determined that thread pipelining is the most efficient method and provides the lowest latency. There is a disadvantage in that not all queries are the same, leading to a problem that not all CPUs are fully used. For example, one could have the query execution used at 100% while the transaction handling is only used at 60% and possibly even less in the receive threads. The send part is flexible, so sending becomes more efficient with larger messages. Therefore, short delays of sending means less CPU load on sending.
The most optimal behavior would be to use thread pipelining but somehow make the transaction threads and receive threads have something useful to do while not being used for receiving or transaction handling. Results showed that the query execution was 40% more effective when executed in a thread on its own, largely due to less pressure on the CPU instruction cache.
RonDB implemented this thread pipelining in 2021. Previously, RonDB had the possibility for threads to assist in read queries, but by adding thread pipelining to RonDB, transaction handling and receive threads assisted on reading queries. However, receive threads cannot be pushed to the limit, otherwise they cannot push enough to the other threads. Overloaded receive threads mean that other threads cannot be fully used.
The read assistance is controlled through a scheduling algorithm discussed later.
ARM support was introduced to RonDB in 2022 through a combined effort with the NDB team at Oracle. This benchmark is the first benchmark where the CPU used in the benchmark is ARM-based.
The Asynchronous NDB API and the selection of placement of transaction coordinator nodes are based on where the data resides, ensuring that we choose the right node for query execution.
Nodes are distributed systems themselves. This means that RonDB needs to also select which thread to execute its read queries. Write queries are sent to the LDM thread that owns their data, but reads can be handled by any thread that is within the same Round Robin group as the owning LDM thread.
Therefore, there needs to be a scheduling algorithm that decides where to send the read queries. This is implemented through an algorithm that checks CPU load once every 50 milliseconds. The load from two such intervals is used to decide the CPU load. Thus, RonDB will react to changes of the CPU load within 50 milliseconds while still taking into account the last 100 milliseconds.
While this reaction time is good, it is not sufficient to achieve the lowest latency variations. The RonDB team added one more level of adaptation to the load. RonDB measures the ques forming to its thread and once every 400 microseconds, RonDB reports the que level to all other threads. This is done through shared memory. Similarly, each thread within a data node collects data from other threads every 400 microseconds, meaning that each thread will see the queuing station within 800 microseconds. This gives RonDB a reaction time to quickly forming queues within less than a millisecond. If the queueing level is similar in the threads, RonDB uses the normal scheduling weights. If a thread gets longer queues, the thread will start receiving less requests.
In RonDB 22.10, we changed RonDB from using MD5 as the hash algorithm to using a modern hash library, decreasing the cost of calculating the hash by a factor of 30.
One of the main reasons the team decided to change from using Go as the implementation language of the RonDB REST API towards using C++ was that this change made it possible to use simdjson. This library improves JSON parser efficiency by a factor of 30. There were other advantages with C++ as well, such as the smaller latency variation due to there not being memory deallocation thread kicking in at random times. In general, the overhead of memory handling in Go made C++ Implementation attractive, even though it required a lot of development time.
It is likely that the REST API server would have required at least 2-3 times more CPU using the Go version of the RonDB REST API, meaning latency would have been worse. The results of this benchmark is, to a large extent, possible because of the conversion to C++.
The first step in the conversion used ChatGPT. ChatGPT can generate code that almost works, but the performance was not close to the level we were looking for. The search for performance improvements still required extensive human labour with expertise in understanding how to write efficient software.
Now we have a working version, it will be fairly easy to extend the REST API server with additional endpoints for inserts, updates, and transactions while still maintaining good performance.
LocationDomainID was introduced several years ago in the NDB Cluster. We had implemented this in RonDB with several issues fixed, such as the aforementioned issue about the placement of cluster connections into receive threads. Other issues were solved in RonDB regarding LocationDomainID.
This benchmark has proven that RonDB is able to handle millions of batch requests of hundreds of rows while maintaining very low latency. Each batch request’s latency averaged roughly 2 milliseconds, even with hundreds of key lookup requests per batch. To achieve this result, there was a wide range of innovations within RonDB that elevated RonDB to become a very competitive product for real-time AI applications and many other real-time applications.
RonDB is available in Kubernetes setup [11], it supports on-line software upgrade/downgrade [12] and there is support for replication between regions [13].
[1] News blog announcing 100M key lookups per second
[2] LocationDomainId feature
(https://mikaelronstrom.blogspot.com/2024/12/release-of-rondb-22107.html)
[3] New hash function
(https://mikaelronstrom.blogspot.com/2023/08/modernising-distributed-hash.html)
[4] ARM64 support
(https://mikaelronstrom.blogspot.com/2022/01/rondb-receives-arm64-support-and-large.html)
[5] Research on Thread Pipelines
(https://mikaelronstrom.blogspot.com/2021/05/research-on-thread-pipelines-using-rondb.html)
[6] Designing a Thread Pipeline
(https://mikaelronstrom.blogspot.com/2021/03/designing-thread-pipeline-for-optimal.html)
[7] Adaptive CPU spinning
(https://mikaelronstrom.blogspot.com/2020/10/adaptive-cpu-spinning-in-ndb-cluster.html)
[8] Asynchronous NDB API
(https://mikaelronstrom.blogspot.com/2020/02/influences-leading-to-asynchronous.html)
[9] RonDB REST API
(https://docs.rondb.com/rondb\_rest\_api/)
[10] RonDB Tools
(https://docs.rondb.com/rondb\_tools/)
[11] RonDB Helm documentation
(https://docs.rondb.com/rondb\_helm/)
[12] RonDB Software Upgrade documentation
(https://docs.rondb.com/rondb\_upgrade/)
[13] RonDB Global Replication documentation
(https://docs.rondb.com/rondb\_global\_intro/)
[14] Reference to simdjson
(https://github.com/simdjson/simdjson)
[15] Blog on 200M key lookups per second
(https://mikaelronstrom.blogspot.com/2015/03/200m-reads-per-second-in-mysql-cluster.html)
[16] Automatic Thread Config
(https://docs.rondb.com/automatic\_thread\_config/)
[17] Reference to https://www.hopsworks.ai/post/rondb-a-real-time-database-for-real-time-ai-systems
[18] Alexanders master thesis
(https://www.diva-portal.org/smash/get/diva2:1556387/FULLTEXT01.pdf)
[19] Blog on 200M key lookups per second
(https://mikaelronstrom.blogspot.com/2015/03/200m-reads-per-second-in-mysql-cluster.html)
Powered by Hopsworks © RonDB 2025. All rights reserved


