

A two-phase commit (2PC) protocol is used in database systems in case data is too large to fit into a single node, requiring storage across multiple partitions and nodes. It ensures that transactions in the database are atomic, meaning either all or none of the nodes apply the changes. There are two main 2PC types: original and linear. RonDB’s uniquely designed 2PC protocol combines elements of both to create a highly available, scalable system that meets low latency, high throughput demands while protecting data and transactions.
If a database becomes too large to fit in a single node, data may need to be partitioned and spread across multiple nodes. Multi-row transactions may then span multiple partitions and nodes, requiring atomicity: either all nodes apply the transaction changes, or none do.
A two-phase commit (2PC) protocol is a popular protocol to ensure atomic transactions. In a 2PC protocol, there is a transaction coordinator (TC) and the participants that contain the data. As indicated in the name, there are generally two phases: prepare and commit. However, there is often an informal, third phase in these protocols: complete. This phase releases locks and clears the commit state of the transaction on each node. With the introduction of the Read Backup feature, transaction acknowledgements are now sent after the complete phase instead of automatically returned in the second phase, creating the (informal) third phase.
The 2PC protocol is generally considered a blocking protocol. “Blocking” occurs if a node fails during a transaction, leaving other nodes undecided about whether to proceed. This is particularly problematic as atomicity must still be guaranteed: either all nodes apply the transaction or none do.
In-memory databases have a greater advantage over disk-based databases, as they can commit a transaction in memory. However, if a node fails, its commit is not immediately durable. When the node recovers, the transaction is gone. The other nodes can decide if they continue or abort the transaction without waiting for a participant node to recover.
A difficult scenario to tackle is when the TC fails after sending out the prepare messages. Participants may wait for the commit message from the TC for an indefinite amount of time. This is where a non-blocking protocol would be useful. A non-blocking protocol, which is another way to say fault-tolerant, would solve this failed TC issue. RonDB’s 2PC protocol is non-blocking, thanks to its specially designed takeover protocol, which will be discussed later in the blog.
Before looking at RonDB’s custom 2PC protocol, it is important to understand the two types of 2PC protocols that are used to help build RonDB’s protocol.
The original 2PC communicates directly between the TC and all participants, where participants do not communicate with each other. This allows high parallelism and low latency but generates many messages, potentially reducing throughput.

One weakness of this protocol is the risk of deadlocks within a row. Because the prepare phase is sent out to all replicas of a row in parallel, there is a chance that two transactions may lock the same row in different replica order, blocking each other.
In linear 2PC, the prepare message is sent serially from the first to the last participant. The commit message then travels back in reverse order to the first participant. The last participant commits the transaction.
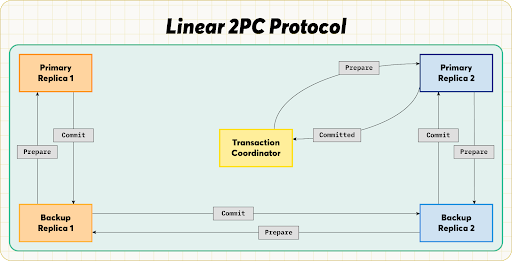
This protocol saves more than half of the messages, improving throughput, but increases latency as more participants are involved. If a transaction spans a large number of rows, the model may achieve unpredictable latency.
Linear 2PC can use primary copy locking to prevent row-level deadlocks by locking the primary replica before backups.
When it came to designing a custom 2PC protocol for RonDB, there were some important properties to consider:
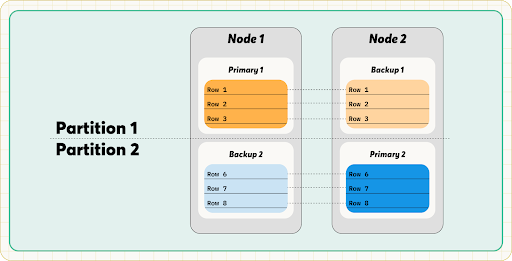
Additionally, RonDB’s 2PC protocol must tackle both atomicity and replication. Databases can use consensus protocols to handle how partitions are replicated, but they must meet certain quorum requirements, meaning that a majority of nodes need to agree on a decision.
Lastly, RonDB’s protocol must support scalability and provide predictable latency.
With all of the above in mind, it seemed beneficial to use a combination of the original protocol and the linear protocol.
To tackle both atomicity and replication, RonDB’s protocol touches all replicas of all partitions. This means the protocol is affected by both the number of replicas (anywhere from 1 to 3) and the number of rows (depending on the transaction) touched by a transaction. To avoid quorum requirements, RonDB uses a fixed node hierarchy defined by cluster-join time and uses a management server or API server as an arbitrator. In case of network partitions, the arbitrator decides which partition can continue. This ensures RonDB’s high availability with two replicas.
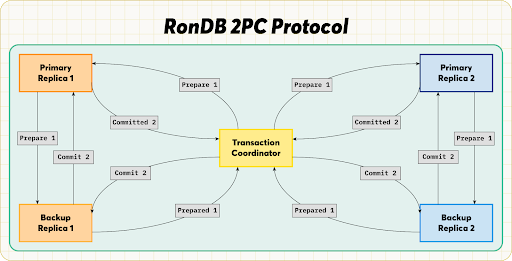
As shown in Figure 4, RonDB’s model uses the parallelism of the original commit protocol for multiple rows while using the linear commit protocol within the replicas of one row. Like the original protocol model, RonDB’s 2PC protocol returns to the TC after the prepare phase, and the TC initiates the commit phase. Because RonDB uses a linear commit within the replicas of a row, RonDB can use primary copy locking to avoid any deadlocks within a row.
Adjusting the linear commit protocol slightly, RonDB’s model returns the commit message in reverse linear order, so that the primary is the last to commit. This is so the primary knows that all other replicas have committed and can safely release its locks without waiting for the complete phase, creating a great advantage where RonDB can read the update directly from the primary replica.
Even though the primaries will have already released their locks, RonDB still runs the complete phase on both the primary and backup replicas to release the commit state on the primaries. The commit state is kept after releasing the locks so that if there is a late-stage TC failure, RonDB can rebuild a TC state. This protects users’ data and transactions. Additionally, the complete phase releases the locks in the backup replicas. Just like the first two phases, this phase is run in parallel for each row.
There are two options when it comes to read-after-write consistency:
This option only allows reading from the primary replica. Latency of writes is decreased, but reads may need to be redirected to the primary. Depending on the geolocational distribution of replicas, latency may be higher for reads.
This option allows reading from any replica. Latency of writes is increased, but reads can be performed from any replica, meaning the latency of reads can be improved by reading from the closest replica.
This is the Read Backup feature, and is enabled by default in RonDB. This can be disabled on a table level.
The ability to disable the Read Backup feature in RonDB is possible due to its reverse linear order with commit messages. When the primary receives the commit message, it knows that all other replicas have committed, and it is safe to release its locks. It is not possible to disable the Read Backup feature in the original or linear 2PC protocols. In those protocols, the primary cannot release its locks before the complete phase has finished, as it does not know whether the backup replicas have been committed or not. RonDB’s special design provides users the option of using the Read Backup feature or not, allowing them to determine whether they want less latency in reads or writes.
With this specially built 2PC protocol, latency is predictable and throughout is reduced when compared to the original protocol. While RonDB’s protocol has a higher latency than the original 2PC protocol, the cost of communication is decreased, and it is expected that users will regain the latency loss at high loads. RonDB’s protocol is built to use a lot of piggybacking, ensuring that the real number of messages is a lot lower.
RonDB’s takeover protocol rebuilds the transaction state at failures, which is possible due to RonDB’s data nodes being part of an integrated active-active system. This is a rather unique possibility, as most modern distributed database solutions’ data servers are also independent databases, which cannot rebuild the transaction state in the event of failures. This enables the takeover protocol to continue, even if there are two simultaneous node features, meaning that unless all of the replicas of a node group fail, RonDB’s takeover protocol will persist.
To start, RonDB’s takeover protocol is initiated by the first TC coordinator thread, located in what is called the master data node (the oldest data node in the cluster). The takeover TC will take over the completion of the transactions. If it doesn’t have enough memory to handle all of the transactions at once, the TC will handle a set of transactions at a time.
Next, each Local Data Manager (LDM) thread (or each LQH block instance) goes through all of the ongoing transactions and sends the information of every transaction that used the failed node as the original TC to the takeover TC. Each LDM notifies the takeover TC once it is finished.
Then, the takeover TC will decide whether each of the transactions should be committed or aborted, depending on how far the transaction has progressed in the process. If any node heard a commit decision, the transaction will be committed. The takeover TC also informs the API nodes of each transaction’s outcome.
There is only one exception where the API nodes are not explicitly informed of a transaction outcome. Before the complete phase has finished, the default Read Backup feature does not allow reporting a transaction as committed, guaranteeing read-after-write consistency on all replicas. With the default Read Backup feature, the complete message is piggy-backed onto the message that reports the completed node failure handling. This is the last message in the protocol, and since all aborted transactions will have already been reported, it is safe to assume that the transaction is committed.
Finally, the takeover protocol reports the completion of node failure handling. This is how RonDB knows that all of the ongoing transactions in the failed node when the crash occurred are either committed or aborted.
If all of the replicas of a node group fail, the cluster fails as well. In that case, RonDB will always need to recover those transactions that are also durable on disk. After recovering, RonDB is no longer blocked due to its Global Checkpoint Protocol. RonDB’s Global Checkpoint Protocol allows recovering from a transaction-consistent state. Transactions that have not been committed by all nodes will not be recoverable; therefore, they will not be blocking.
RonDB’s specially built Takeover Protocol ensures that users’ data and transactions are not lost in case of a node failure and is built to survive multiple crashes, so that users can always access their data. With RonDB’s Takeover Protocol, users don’t need to worry about what could happen to their application and its data because RonDB is built to consistently run smoothly despite any disruptions.
Through combining the strengths of the original and linear 2PC protocols, RonDB’s 2PC protocol brings predictable latency, high throughput, and data consistency. RonDB’s 2PC protocol is built to be fault-tolerant with its unique takeover protocol, ensuring that transactions are either completed or aborted, and it is successfully reported. The unique 2PC structure enables more flexibility for developers, such as the ability to turn off the Read Backup feature. RonDB’s 2PC protocol is built to support a database that demands low latency, high availability, and high throughput.
This Blog was edited by Mikael Ronström and Gretchen Short.
Download the latest RonDB version
Powered by Hopsworks © RonDB 2025. All rights reserved


